
За 15 минут до этой фотографии тумана не было.
За 15 минут до этой фотографии тумана не было.

До сих пор удивляюсь, откуда это растение берёт воду.

Угадайте оперу по костюмам.
Если выполнить SQL-запрос:
- SELECT id FROM <таблица>
то весьма вероятно он не только выполнится без ошибок, но и вернёт множество (в самом хорошем, математическом, смысле этого слова) целых чисел.
Многие программисты, с которыми я знаком, добавляют во все создаваемые таблицы столбец с автоматически генерируемыми монотонно возрастающими целыми числами и делают его первичным ключом. Однако, когда я спрашиваю, зачем это нужно, я редко получаю разумные аргументы в ответ. Большинство отвечает просто «все так делают» или «просто привыкли». Как вы знаете, привычки бывают полезными и вредными. В этой записи я постараюсь показать, что привычка добавлять автоинкрементный столбец и делать его первичным ключом может быть весьма вредной.
Давайте вспомним, зачем вообще нужны первичные ключи. Распространённая, хоть и неправильная, точка зрения состоит в том, что первичный ключ позволяет однозначно идентифицировать строку в таблице. Это неправильное понимание причины и следствия. На самом деле первичные ключи необходимы для гарантированного отсутствия повторяющихся строк.
Когда требование отсутствия повторяющихся строк уже выполнено, можно утверждать, что первичный ключ однозначно определяет конкретную строку в таблице. Если мы рассмотрим это более строго, то можно сказать, что как сам первичный ключ целиком, так и подмножество столбцов первичного ключа (в случае составного ключа), и даже столбцы, не входящие в первичный ключ (что часто наблюдается, когда программисты бездумно создают суррогатные ключи), могут однозначно указывать на конкретную строку. Все это зависит от того, как спроектирована таблица.
Однако, давайте вернемся к основной цели нашего разговора. Мы уже установили, что первичный ключ необходим для гарантии отсутствия повторяющихся строк и является способом «усиления семантики». Добавляя столбец с гарантированно уникальным значением, вы не вносите ничего нового с точки зрения данных, а лишь создаете иллюзию хорошо спроектированной таблицы. В действительности, вы можете создать любое количество записей, которые будут идентичны во всех столбцах, кроме столбца с суррогатным ключом. Я не буду описывать проблемы, к которым это может привести, так как уверен, что вы сами понимаете, почему такие таблицы являются очень плохой идеей.
На этом этапе многие могут возразить, утверждая, что использование «естественного» составного первичного ключа и передача его из родительской таблицы в дочернюю является плохой идеей. Это разумное замечание. Я сам являюсь не только теоретиком, а также практиком, и поэтому в таких ситуациях рекомендую использовать суррогатный ключ с обязательным наложением ограничения уникальности на потенциальный ключ. Таким образом, мы одновременно защищаемся от появления семантически идентичных строк в таблице и получаем возможность передавать в процедуры, запросы и дочерние таблицы короткое целочисленное значение. Кроме того, стоит помнить, что чем короче ключ, тем более эффективно работают ограничения FOREIGN KEY и операции соединения, а также требуется меньше места для хранения ключа в связанных таблицах.
Безусловно, существуют и другие ситуации, когда суррогатные ключи необходимы. Например, в организациях часто используются табельные номера сотрудников, что является идеальным примером для применения автоинкрементных уникальных значений. На самом деле, каждый из вас сможет придумать множество ситуаций, когда использование суррогатных ключей оправдано. Однако, прошу вас не применять их бездумно в каждой таблице! И если вам все же необходимы суррогатные ключи, то стоит задуматься, не будет ли лучшим решением использование GUID-ов вместо автоинкрементных значений.

Сначала я узнал, про замёрзший фонтан высотой несколько метров, и только потом про радиоактивное загрязнение.

Когда-нибудь, у меня полноценный длиннофокусный объектив или даже телескоп. Пока так.

Всю жизнь думал, что у меня нет аллергии, а теперь думаю, что есть. Узнать бы ещё, что это за растение.

Когда-нибудь я научусь фотографировать салюты. Наверное.
Не секрет, что один и тот же запрос можно написать с помощью SQL множеством разных способов. В идеальном мире с безупречным оптимизатором все эти способы должны работать за одинаковое время. Но, к счастью, наш мир не идеален, и оптимизаторы тоже довольно далеки от совершенства. Именно поэтому у программистов до сих пор есть работа.
Обычно проблемы с производительностью решаются с помощью индексов. В принципе это правильный подход, но всегда нужно помнить, что индексы требуют дополнительное дисковое пространство и негативно влияют на скорость операций изменения данных. Сегодня я предлагаю рассмотреть простой запрос, и попытаться ускорить его не используя индексы, а просто меняя его формулировку на SQL.
Нам предстоит работать с таблицей person из примерно 300 тысяч строк следующего вида:
| id | first_name | middle_name | last_name | mother_id | father_id |
|---|---|---|---|---|---|
| Уникальный идентификатор человека | Имя | Отчество | Фамилия | Ссылка на id матери в этой же таблице (person) | Ссылка на id отца в этой же таблице (person) |
Задача довольно тривиальная — необходимо подсчитать количество детей у каждого человека. То есть на выходе требуется таблица вида:
| id | first_name | middle_name | last_name | child_cnt |
|---|---|---|---|---|
| Уникальный идентификатор человека | Имя | Отчество | Фамилия | Количество детей у указанного человека |
Самый тривиальный вариант, который обычно пишут новички в SQL содержит подзапрос в списке столбцов:
- SELECT p.id,
- p.last_name,
- p.first_name,
- p.middle_name,
- (
- SELECT COUNT(*) AS child_cnt
- FROM dbo.person pp
- WHERE pp.father_id = p.id
- OR pp.mother_id = p.id
- ) AS child_cnt
- FROM dbo.person p
- ORDER BY p.id;
Надеюсь, вы понимаете в чём проблема этого запроса. Для каждой(!) строки результирующей выборки (а их 300 тысяч) будет выполнен подзапрос с подсчётом количества детей. Суммарная стоимость этого варианта составляет 178230. Что касается времени выполнения, то я так и не дождался результата, поэтому условно будем считать час (на самом деле намного больше).

Казалось бы очевидным улучшением является подсчёт количества детей с помощью соединения таблицы с собой:
- SELECT p.id,
- COUNT(p2.father_id)+COUNT(p2.mother_id) AS child_cnt
- FROM dbo.person p
- LEFT JOIN dbo.person p2
- ON p2.father_id = p.id
- OR p2.mother_id = p.id
- GROUP BY p.id;
Но оптимизатор так не считает. Оценка этого варианта 455435, а в плане виден ненавистный спулинг.

Тем не менее если мы заменим left join на inner join, мы получим список только тех людей, у кого есть хотя бы один ребёнок, но зато с оценкой в ~64.

Путём небольшой доработки, мы сможем добавить информацию о людях без детей и получим запрос, который вернёт нам ровно ту информацию, которая требуется:
- SELECT p.id,
- p.last_name,
- p.first_name,
- p.middle_name,
- COALESCE(r.child_cnt, 0) AS child_cnt
- FROM dbo.person p
- LEFT JOIN
- (
- SELECT p.id,
- COUNT(*) AS child_cnt
- FROM dbo.person p
- INNER JOIN dbo.person p2
- ON p2.father_id = p.id
- OR p2.mother_id = p.id
- GROUP BY p.id
- ) r
- ON p.id = r.id;
Время выполнения этого запроса девять секунд. В принципе, на этом можно было бы остановиться, но ради спортивного интереса продолжим.
Очевидно, что идея подсчитать количество детей для тех, у кого они есть, а потом дополнить этот список оставшимися людьми довольно эффективная. Так как «обёртка»-дополнение во всех случаях будет одинаковой , сосредоточимся на подсчёте детей у тех, у кого они есть.
- SELECT p.id,
- COUNT(*) AS child_cnt
- FROM dbo.person p
- INNER JOIN dbo.person p2
- ON p2.father_id = p.id
- GROUP BY p.id
- UNION ALL
- SELECT p.id,
- COUNT(*) AS child_cnt
- FROM dbo.person p
- INNER JOIN dbo.person p2
- ON p2.mother_id = p.id
- GROUP BY p.id;
В этом варианте запроса с оценкой ~15, мы избавляемся от сложного оператора OR в join. Вместо этого мы подсчитываем у скольких людей конкретная персона является отцом, аналогично считаем у скольких людей она является матерью, а результаты просто объединяем.
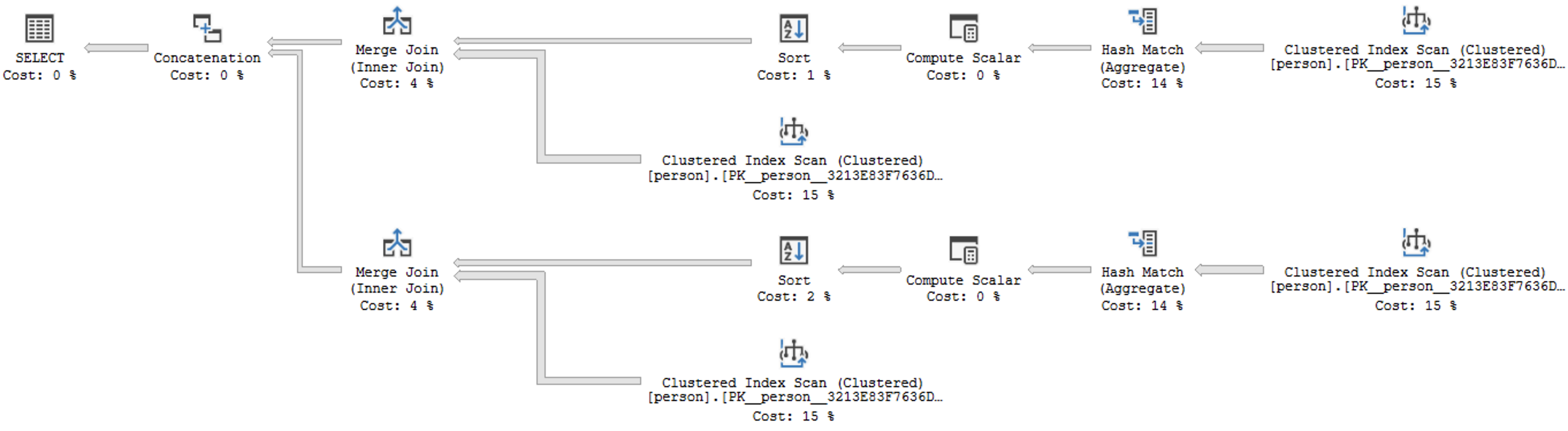
Но на самом деле можно поступить ещё проще. Нам нет необходимости проверять каждую персону на наличие детей. Мы можем просто посчитать сколько раз каждый человек появлялся в столбцах mother_id / father_id и таким образом получить искомое количество детей.
- SELECT r.parent_id,
- COUNT(*) AS child_cnt
- FROM
- (
- SELECT mother_id AS parent_id
- FROM dbo.person
- WHERE (1 = 1)
- AND (mother_id IS NOT NULL)
- UNION ALL
- SELECT father_id
- FROM dbo.person
- WHERE (1 = 1)
- AND (father_id IS NOT NULL)
- ) r
- GROUP BY r.parent_id;
С оценкой ~5 мы считаем требуемые данные всего за одну секунду.
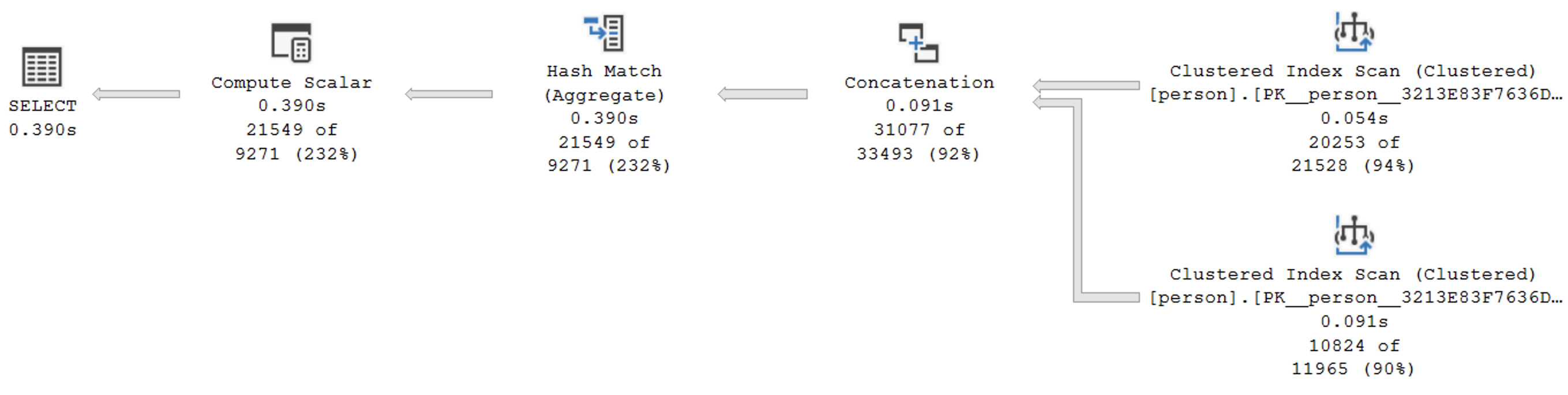
Разумеется, как я сказал ещё в самом начале, гораздо проще было бы ускорить этот запрос, просто добавив индекс. Но разве не здорово просто переформулировав то, что ты хочешь получить от сервера, добиться ускорения в сотни раз?
—
Уже после публикации этой записи мне пришла в голову ещё одна идея. Очевидно, что использование OR в подзапросе существенно замедляет его. Что если оставить подзапрос в SELECT, но при этом разбить его на две части?
- SELECT p.id,
- p.last_name,
- p.first_name,
- p.middle_name,
- (
- SELECT COUNT(*) AS child_cnt
- FROM dbo.person pp
- WHERE pp.father_id = p.id
- ) +
- (
- SELECT COUNT(*) AS child_cnt
- FROM dbo.person pp
- WHERE pp.mother_id = p.id
- ) AS child_cnt
- FROM dbo.person p
- ORDER BY p.id;

Мы видим, что при таком запросе оптимизатор догадался сначала сгруппировать данные по матерям и отцам, а потом собрать итоговую таблицу используя быстрый MERGE JOIN.
Даже такой оптимизации уже было бы достаточно и вместо долгого ожидания мы бы получили результат всего за несколько секунд.

Сейчас так уже не делают.