Не секрет, что один и тот же запрос можно написать с помощью SQL множеством разных способов. В идеальном мире с безупречным оптимизатором все эти способы должны работать за одинаковое время. Но, к счастью, наш мир не идеален, и оптимизаторы тоже довольно далеки от совершенства. Именно поэтому у программистов до сих пор есть работа.
Обычно проблемы с производительностью решаются с помощью индексов. В принципе это правильный подход, но всегда нужно помнить, что индексы требуют дополнительное дисковое пространство и негативно влияют на скорость операций изменения данных. Сегодня я предлагаю рассмотреть простой запрос, и попытаться ускорить его не используя индексы, а просто меняя его формулировку на SQL.
Нам предстоит работать с таблицей person из примерно 300 тысяч строк следующего вида:
| id | first_name | middle_name | last_name | mother_id | father_id |
|---|---|---|---|---|---|
| Уникальный идентификатор человека | Имя | Отчество | Фамилия | Ссылка на id матери в этой же таблице (person) | Ссылка на id отца в этой же таблице (person) |
Задача довольно тривиальная — необходимо подсчитать количество детей у каждого человека. То есть на выходе требуется таблица вида:
| id | first_name | middle_name | last_name | child_cnt |
|---|---|---|---|---|
| Уникальный идентификатор человека | Имя | Отчество | Фамилия | Количество детей у указанного человека |
Самый тривиальный вариант, который обычно пишут новички в SQL содержит подзапрос в списке столбцов:
- SELECT p.id,
- p.last_name,
- p.first_name,
- p.middle_name,
- (
- SELECT COUNT(*) AS child_cnt
- FROM dbo.person pp
- WHERE pp.father_id = p.id
- OR pp.mother_id = p.id
- ) AS child_cnt
- FROM dbo.person p
- ORDER BY p.id;
Надеюсь, вы понимаете в чём проблема этого запроса. Для каждой(!) строки результирующей выборки (а их 300 тысяч) будет выполнен подзапрос с подсчётом количества детей. Суммарная стоимость этого варианта составляет 178230. Что касается времени выполнения, то я так и не дождался результата, поэтому условно будем считать час (на самом деле намного больше).

Казалось бы очевидным улучшением является подсчёт количества детей с помощью соединения таблицы с собой:
- SELECT p.id,
- COUNT(p2.father_id)+COUNT(p2.mother_id) AS child_cnt
- FROM dbo.person p
- LEFT JOIN dbo.person p2
- ON p2.father_id = p.id
- OR p2.mother_id = p.id
- GROUP BY p.id;
Но оптимизатор так не считает. Оценка этого варианта 455435, а в плане виден ненавистный спулинг.

Тем не менее если мы заменим left join на inner join, мы получим список только тех людей, у кого есть хотя бы один ребёнок, но зато с оценкой в ~64.

Путём небольшой доработки, мы сможем добавить информацию о людях без детей и получим запрос, который вернёт нам ровно ту информацию, которая требуется:
- SELECT p.id,
- p.last_name,
- p.first_name,
- p.middle_name,
- COALESCE(r.child_cnt, 0) AS child_cnt
- FROM dbo.person p
- LEFT JOIN
- (
- SELECT p.id,
- COUNT(*) AS child_cnt
- FROM dbo.person p
- INNER JOIN dbo.person p2
- ON p2.father_id = p.id
- OR p2.mother_id = p.id
- GROUP BY p.id
- ) r
- ON p.id = r.id;
Время выполнения этого запроса девять секунд. В принципе, на этом можно было бы остановиться, но ради спортивного интереса продолжим.
Очевидно, что идея подсчитать количество детей для тех, у кого они есть, а потом дополнить этот список оставшимися людьми довольно эффективная. Так как «обёртка»-дополнение во всех случаях будет одинаковой , сосредоточимся на подсчёте детей у тех, у кого они есть.
- SELECT p.id,
- COUNT(*) AS child_cnt
- FROM dbo.person p
- INNER JOIN dbo.person p2
- ON p2.father_id = p.id
- GROUP BY p.id
- UNION ALL
- SELECT p.id,
- COUNT(*) AS child_cnt
- FROM dbo.person p
- INNER JOIN dbo.person p2
- ON p2.mother_id = p.id
- GROUP BY p.id;
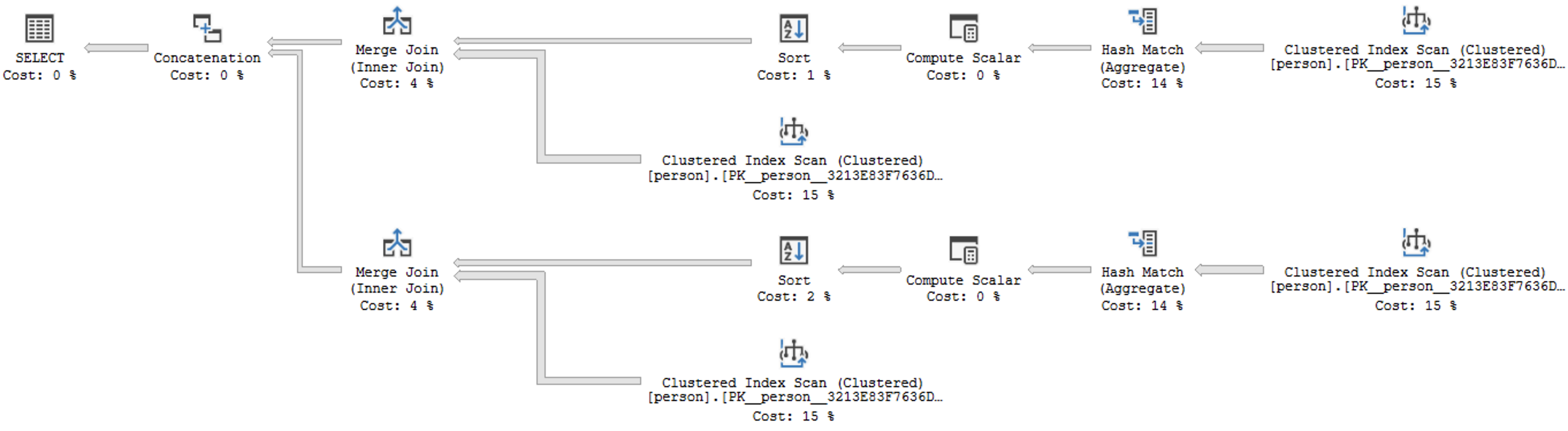
В этом варианте запроса с оценкой ~15, мы избавляемся от сложного оператора OR в join. Вместо этого мы подсчитываем у скольких людей конкретная персона является отцом, аналогично считаем у скольких людей она является матерью, а результаты просто объединяем.
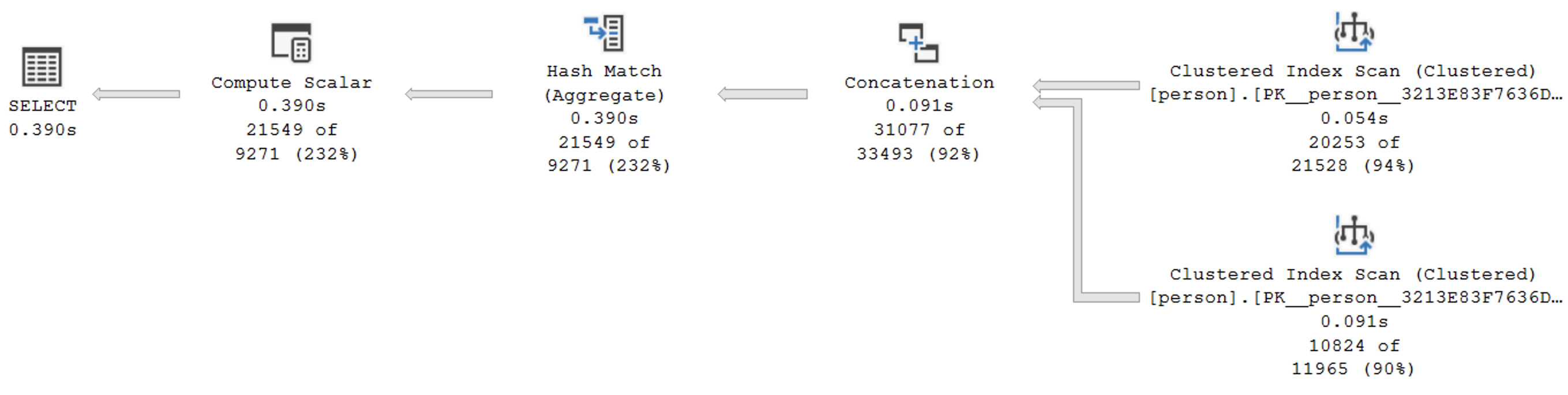
Но на самом деле можно поступить ещё проще. Нам нет необходимости проверять каждую персону на наличие детей. Мы можем просто посчитать сколько раз каждый человек появлялся в столбцах mother_id / father_id и таким образом получить искомое количество детей.
- SELECT r.parent_id,
- COUNT(*) AS child_cnt
- FROM
- (
- SELECT mother_id AS parent_id
- FROM dbo.person
- WHERE (1 = 1)
- AND (mother_id IS NOT NULL)
- UNION ALL
- SELECT father_id
- FROM dbo.person
- WHERE (1 = 1)
- AND (father_id IS NOT NULL)
- ) r
- GROUP BY r.parent_id;
С оценкой ~5 мы считаем требуемые данные всего за одну секунду.
Разумеется, как я сказал ещё в самом начале, гораздо проще было бы ускорить этот запрос, просто добавив индекс. Но разве не здорово просто переформулировав то, что ты хочешь получить от сервера, добиться ускорения в сотни раз?
—
Уже после публикации этой записи мне пришла в голову ещё одна идея. Очевидно, что использование OR в подзапросе существенно замедляет его. Что если оставить подзапрос в SELECT, но при этом разбить его на две части?
- SELECT p.id,
- p.last_name,
- p.first_name,
- p.middle_name,
- (
- SELECT COUNT(*) AS child_cnt
- FROM dbo.person pp
- WHERE pp.father_id = p.id
- ) +
- (
- SELECT COUNT(*) AS child_cnt
- FROM dbo.person pp
- WHERE pp.mother_id = p.id
- ) AS child_cnt
- FROM dbo.person p
- ORDER BY p.id;

Мы видим, что при таком запросе оптимизатор догадался сначала сгруппировать данные по матерям и отцам, а потом собрать итоговую таблицу используя быстрый MERGE JOIN.
Даже такой оптимизации уже было бы достаточно и вместо долгого ожидания мы бы получили результат всего за несколько секунд.