
Тарелка или купол?
Тарелка или купол?

Когда ты сам своего рода миллионер.


Здешние пески холодные.

Больше полугода назад я завёл креветок Galaxy fishbone. С точки зрения биологии это обычная Caridina, но коллекционеры ценят таких креветок за необычный окрас. Из-за долгой и сложной селекции эти креветки менее стойкие, чем их природные родственники. У меня даже были сомнения, получится ли разводить их в домашнем аквариуме. Но сегодня, когда я увидел первого креветёнка, сомнения развеялись. Начало положено.
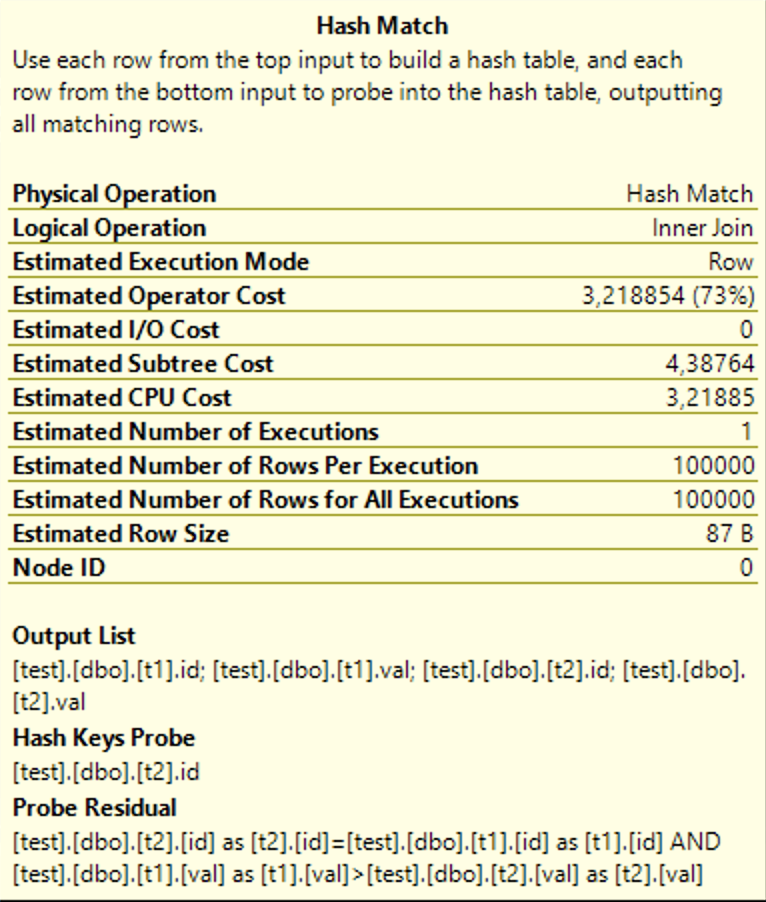
Долгое время я был уверен, что особенностью hash join является тот факт, что он работает только с условиями строгого равенства в соединениях. Это довольно логично, если вспомнить, как работают hash-функции.
Основная идея заключается в том, что можно отобразить множество значений из таблицы в менее мощное множество. Например, вместо того, чтобы сравнивать два целых числа (они могут быть в диапазоне от -2 147 483 648 до 2 147 483 647), мы можем сравнить остатки от их деления на 17 (весь диапазон значений лежит от 0 до 16). Если остатки от деления не совпадают, то мы можем уверенно сказать, что и сами числа не совпадут. Если же остатки совпали, то надо в явном виде проверить сами числа, чтобы избежать ошибок из-за коллизий. Выигрыш здесь получается за счёт того, что процент совпадений хороших hash-функций обычно мал, и мы можем сразу отсекать большие объёмы данных. Явным недостатком предложенного метода является то, что для из того, что a>b не следует, что hash(a)>hash(b). Например 18>5, но 18 mod 17 = 1 < 5 mod 17 = 5. Таким образом получается, что hash может использоваться только тогда, когда в условии соединения строгое равенство.
Я и многие мои знакомые думали, что это верно всегда, т.е. даже в составном условии соединения все условия должны быть равенствами, а на практике оказалось, что hash join может использоваться если в условии соединения есть хотя бы одно равенство. В качестве примера создадим две таблички (t1 и t2) и заполним их записями по следующему шаблону:
CREATE TABLE t1
(
id INT IDENTITY(1, 1),
val CHAR(36)
);
GO
DECLARE @Counter INT = 1;
WHILE (@Counter <= 100000)
BEGIN
INSERT dbo.t2
(
val
)
VALUES
(NEWID());
SET @Counter = @Counter + 1;
END;
Ещё пару дней назад я бы сказал, что в запросе точно будет использоваться Nested Loops, но сервер оказался хитрее
SELECT t1.id,
t1.val,
t2.id,
t2.val
FROM dbo.t1 t1
INNER JOIN dbo.t2 t2
ON (t2.id = t1.id)
AND (t1.val > t2.val);
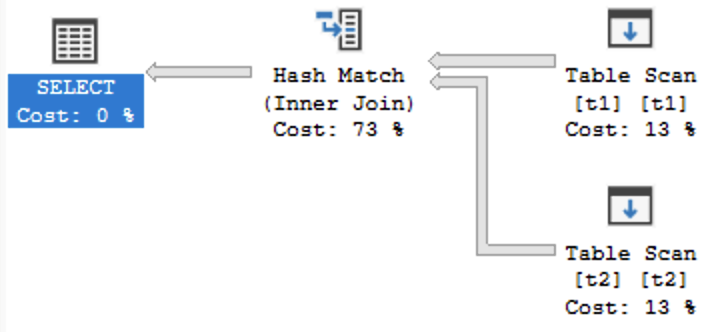
Если у вас возник вопрос, как тут можно использовать hash join, то хитрость вот в чём: по hash-функции сравнивается только поле id (Hash Keys Probe), при несовпадении хешей строка сразу отбрасывается, а при совпадении происходит полное сравнение и id, и val (Probe Residual).
Есть такая игра WORDLE, в которой нужно угадывать слова. Ты предлагаешь игре пятибуквенное слово, а она в ответ красит буквы зелёным, если они есть в угадываемом слове и стоят на правильных местах, жёлтым если они есть в угадываемом слове, но на других местах, и серым, если этих букв в слове нет. Цель — отгадать слово не более, чем за шесть попыток.
Я в своё время написал скрипт, который перебрал тройки пятибуквенных слов и нашёл трио слов, которое открывает 15 самых частоиспользуемых букв.
Сейчас появилась версия этой игры для шести-, семи-, восьми- и даже девятибуквенных слов. Поэтому вопрос поиска оптимальных троек встал с новой силой. Предлагаю вам поупражняться в SQL и предложить подходы, которые позволят найти оптимальные слова за разумное время и при этом не положить сервер. Если решите попробовать на боевых данных, оставьте в комментариях свою почту или telegram, пришлю скрипт заполнения словаря.
Оператор ASSERT используется для проверки определённых условий. Это оператор будет выполняться для каждой строки из набора данных.
Типичный пример, когда можно встретить этот оператор — проверка условия CHECK. Например, для столба можно ограничить список возможных значений. Тогда при вставке данных ASSERT будет проверять для каждой строки значение, переданное в столбец. К сожалению в реальной работе эти возможности SQL используют реже, чем следует. Поэтому мы рассмотрим выдуманный и сильно упрощённый пример.
DROP TABLE IF EXISTS traffic_light; CREATE TABLE traffic_light ( id INT IDENTITY(1, 1), color CHAR(1), CONSTRAINT CHECK_COLOR CHECK (color IN ( 'G', 'R' )) ); INSERT INTO dbo.traffic_light (color) VALUES ('Y');
В этой таблице мы разрешаем цвету условного светофора быть или зелёным, или красным. При вставке данных в эту таблицу SQL Server генерирует следующий план:


Если разобраться с тем, что именно проверяет ASSERT, то мы увидим, что он возвращает 0, если в столбец color передаётся значение отличное от G или R и NULL в противном случае. Ошибка будет сгенерирована, есть ASSERT вернёт значение отличное от NULL.
Помимо проверки CHECK-ограничений ASSERT используется и при проверке ограничений внешних ключей. Попробуем чуть усложнить наш пример, добавив ещё одну таблицу с потенциально возможными цветами светофора и связав две таблицы между собой.
DROP TABLE IF EXISTS possible_light; CREATE TABLE possible_light ( color CHAR(1) PRIMARY KEY ); INSERT INTO dbo.possible_light (color) VALUES ('R'),('Y'),('G'); ALTER TABLE dbo.traffic_light ADD CONSTRAINT fk_light FOREIGN KEY (color) REFERENCES dbo.possible_light (color);
Теперь при вставке данных в первую таблицу план усложнится:

Если идти справа налево, то первый ASSERT как и раньше проверит CHECK ограничение, а второй ASSERT проверит корректность связи по ключам.
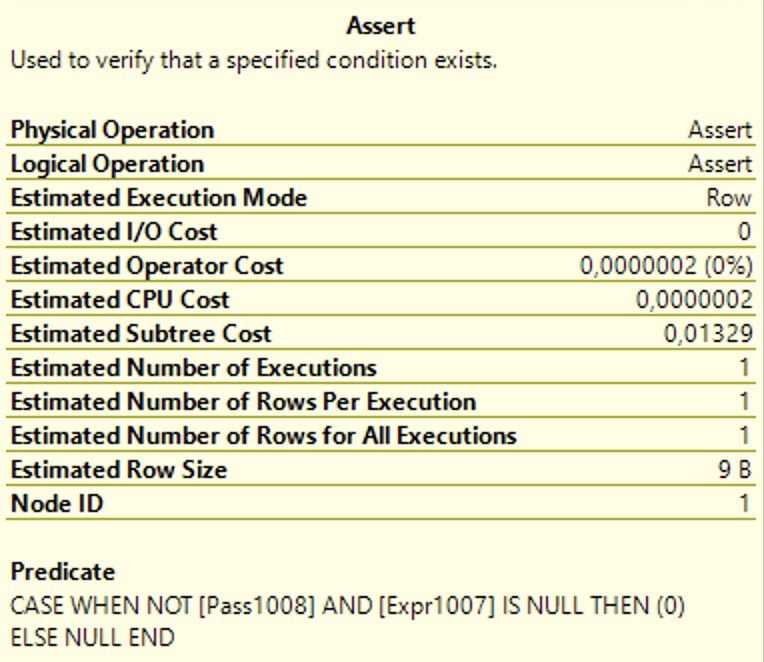
В предикате второго оператора ASSERT мы видим непонятное условие Expr1007, но всё станет на свои места, если отобразить план запроса в виде текста:
|--Assert(WHERE:(CASE WHEN NOT [Pass1008] AND [Expr1007] IS NULL THEN (0) ELSE NULL END)) |--Nested Loops(Left Semi Join, PASSTHRU:([lessons].[dbo].[traffic_light].[color] IS NULL), OUTER REFERENCES:([lessons].[dbo].[traffic_light].[color]), DEFINE:([Expr1007] = [PROBE VALUE])) |--Assert(WHERE:(CASE WHEN [lessons].[dbo].[traffic_light].[color]<>'R' AND [lessons].[dbo].[traffic_light].[color]<>'G' THEN (0) ELSE NULL END)) | |--Table Insert(OBJECT:([lessons].[dbo].[traffic_light]), SET:([lessons].[dbo].[traffic_light].[color] = [Expr1004],[lessons].[dbo].[traffic_light].[id] = [Expr1003])) | |--Compute Scalar(DEFINE:([Expr1004]=CONVERT_IMPLICIT(char(1),[@1],0))) | |--Compute Scalar(DEFINE:([Expr1003]=getidentity((1525580473),(6),NULL))) | |--Constant Scan |--Clustered Index Seek(OBJECT:([lessons].[dbo].[possible_light].[PK__possible__900DC6E8209DDE1B]), SEEK:([lessons].[dbo].[possible_light].[color]=[lessons].[dbo].[traffic_light].[color]) ORDERED FORWARD)
По строке DEFINE:([Expr1007] = [PROBE VALUE]) становится понятно, что это выражение — просто результат объединения таблиц. Этим выражением ASSERT проверяет, что вставляемое значение действительно есть в таблице possible_light.
Наконец, рассмотрим ещё один случай, где оператор ASSERT может встречаться в реальной работе. Речь идёт о подзапросах. Во многих ситуациях встречается «скалярный» подзапрос. Т.е. такой подзапрос, который возвращает строго одно значение. В качестве тестового запроса рассмотрим следующий код:
SELECT * FROM dbo.traffic_light tl WHERE (tl.color> (SELECT pl.color FROM dbo.possible_light pl WHERE (1=1)and(pl.color>'A')) )
Практического смысла он не несёт, но позволяет продемонстрировать ситуацию, когда мы сравниваем скалярное значение с результатом подзапроса. План получился не очень сложный:

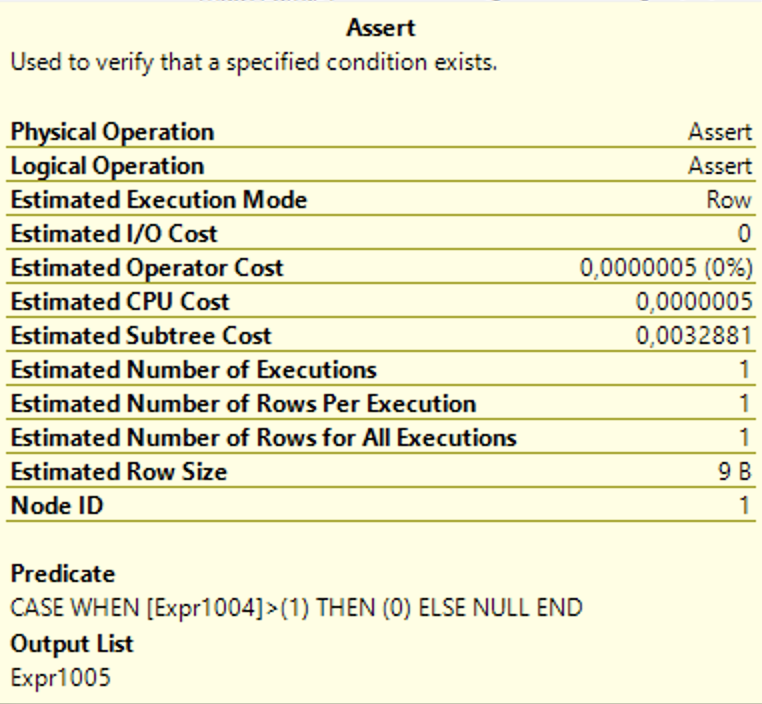
Самый интересный блок тут это часть где данные из possible_light агрегируются, чтобы подсчитать количество строк, а потом полученное значение передаётся в ASSERT. Думаю, вы уже сами догадались, что Expr1004 это результат агрегации
Stream Aggregate(DEFINE:([Expr1004]=Count(*)...
Вот такой большой пост у меня получился о простейшем, но очень важном операторе.

Торговое название этой креветки «золотой дракон». Почему «золотой» понятно, но вот про «дракона» я не понял. Если у вас есть версия, пишите в комментариях. Относится к селекционным видам. В остальном ничего особенного. Обычная креветка-каридина.

В горы ходить вообще не круто.