Долгое время я был уверен, что особенностью hash join является тот факт, что он работает только с условиями строгого равенства в соединениях. Это довольно логично, если вспомнить, как работают hash-функции.
Основная идея заключается в том, что можно отобразить множество значений из таблицы в менее мощное множество. Например, вместо того, чтобы сравнивать два целых числа (они могут быть в диапазоне от -2 147 483 648 до 2 147 483 647), мы можем сравнить остатки от их деления на 17 (весь диапазон значений лежит от 0 до 16). Если остатки от деления не совпадают, то мы можем уверенно сказать, что и сами числа не совпадут. Если же остатки совпали, то надо в явном виде проверить сами числа, чтобы избежать ошибок из-за коллизий. Выигрыш здесь получается за счёт того, что процент совпадений хороших hash-функций обычно мал, и мы можем сразу отсекать большие объёмы данных. Явным недостатком предложенного метода является то, что для из того, что a>b не следует, что hash(a)>hash(b). Например 18>5, но 18 mod 17 = 1 < 5 mod 17 = 5. Таким образом получается, что hash может использоваться только тогда, когда в условии соединения строгое равенство.
Я и многие мои знакомые думали, что это верно всегда, т.е. даже в составном условии соединения все условия должны быть равенствами, а на практике оказалось, что hash join может использоваться если в условии соединения есть хотя бы одно равенство. В качестве примера создадим две таблички (t1 и t2) и заполним их записями по следующему шаблону:
CREATE TABLE t1
(
id INT IDENTITY(1, 1),
val CHAR(36)
);
GO
DECLARE @Counter INT = 1;
WHILE (@Counter <= 100000)
BEGIN
INSERT dbo.t2
(
val
)
VALUES
(NEWID());
SET @Counter = @Counter + 1;
END;
Ещё пару дней назад я бы сказал, что в запросе точно будет использоваться Nested Loops, но сервер оказался хитрее
SELECT t1.id,
t1.val,
t2.id,
t2.val
FROM dbo.t1 t1
INNER JOIN dbo.t2 t2
ON (t2.id = t1.id)
AND (t1.val > t2.val);
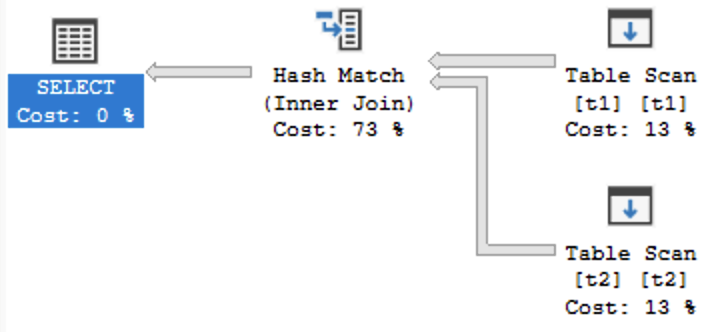
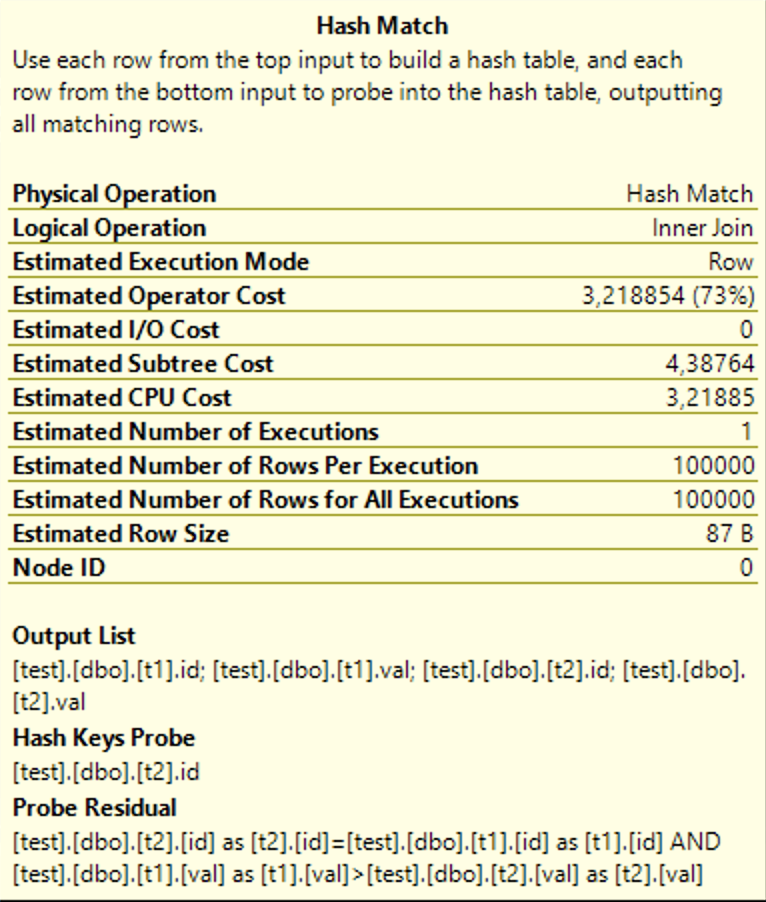
Если у вас возник вопрос, как тут можно использовать hash join, то хитрость вот в чём: по hash-функции сравнивается только поле id (Hash Keys Probe), при несовпадении хешей строка сразу отбрасывается, а при совпадении происходит полное сравнение и id, и val (Probe Residual).
2 ответа к “hash join и операторы сравнения”
эт какая дб? по скринам не ясна…
Это MS SQL Server.